
当地域特定的海参品种——仿刺参,在亚洲国家一直以来都被食用和应用于医疗领域,因为它被认为具有多种保健功能。在中国共有20多种食用海参,广泛分布于黄海、渤海和东海地区。
黄海和渤海是刺参等优质海参的主要产地,刺参被认为是最有价值的海参品种之一,在中国市场有着较大的份额。
以总脂肪含量作为OPS算法建立识别模型的波长区域选择指标,总脂肪含量和脂肪剖面被用作生物标志物,已被成功用于确认和追溯海参的地理起源。
类似的方法已在中国蜂胶和延胡索块茎的产地溯源识别中得到应用,采用主成分分析结合马哈拉诺比斯距离算法和缩放到第一范围算法。
由于生长在不同海域的同种海参具有不同的品质和药用用途,而且很容易被混淆,难以通过感官方法进行鉴别。刺参的产地成为影响其价格和消费者偏好的主要因素之一。
有些人采取混淆产地、以次充好、掺假等不法手段,导致了无良竞争,损害了消费者利益和地理标志海参的声誉,建立快速、可行的海参来源识别和追溯方法变得尤为紧迫。
为了解决这些食品安全问题,已经开展了大量关于海参产地溯源和鉴定的研究工作。一些方法包括多元素分析和稳定同位素比和脂肪酸谱分析,但它们通常耗时复杂或需要繁琐的样品制备。

采用快速准确的控制方法,其中一种常见选择是使用近红外光谱技术,结合化学计量学方法。NIRS技术省时经济,无需复杂的样品处理,被广泛用于认证、原产地追溯、食品安全问题辨别等领域。
在很多关于海鲜质量控制、产地区分和近红外光谱分析含量测定的研究已经报道,目前尚未有报道使用近红外光谱技术对新鲜海参的产地进行鉴定。
具体目标包括:选择合适的波长区域,通过OPS算法获得最佳的刺参来源识别结果,利用PCA-MD建立NIRS识别模型,并借助缩放到第一范围算法鉴定刺参的来源,以及开发刺参总脂肪含量的NIRS定量模型,采用偏最小二乘回归方法对刺参进行量化分析。
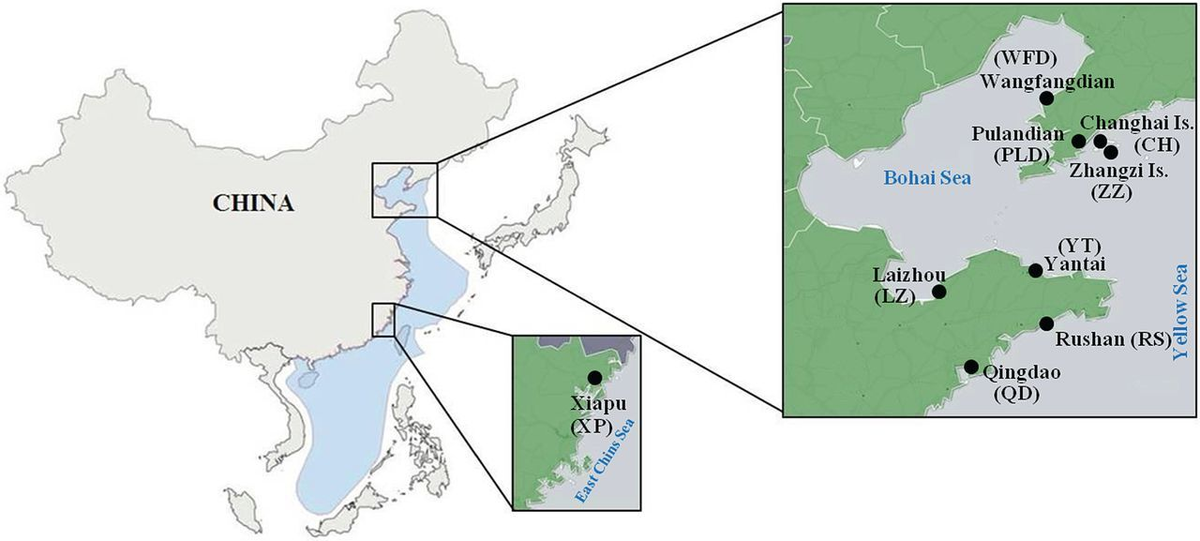
从北海和东海的刺参主产区,共计9个生境采集了189份刺参样本。所有样本都生长在深海30米深的自然环境中,未经人工饲养。采样后立即解剖每个样品,并清理其消化道。体壁保存在-20°C的冰箱中,并在取样后的2天内运送至实验室。
将每个样本的体壁横切成两个均匀的部分。其中,Part-A部分在光谱采集前没有进行任何预处理,而Part-A’部分则用于测定总脂肪含量。A’部分被冷冻干燥并保存,然后进行研磨并过筛保存。
光谱采集过程中,为了尽量减少人为因素引起的偏差,每个刺参样本被放入试管中,并插入反射光纤探头以记录近红外光谱。
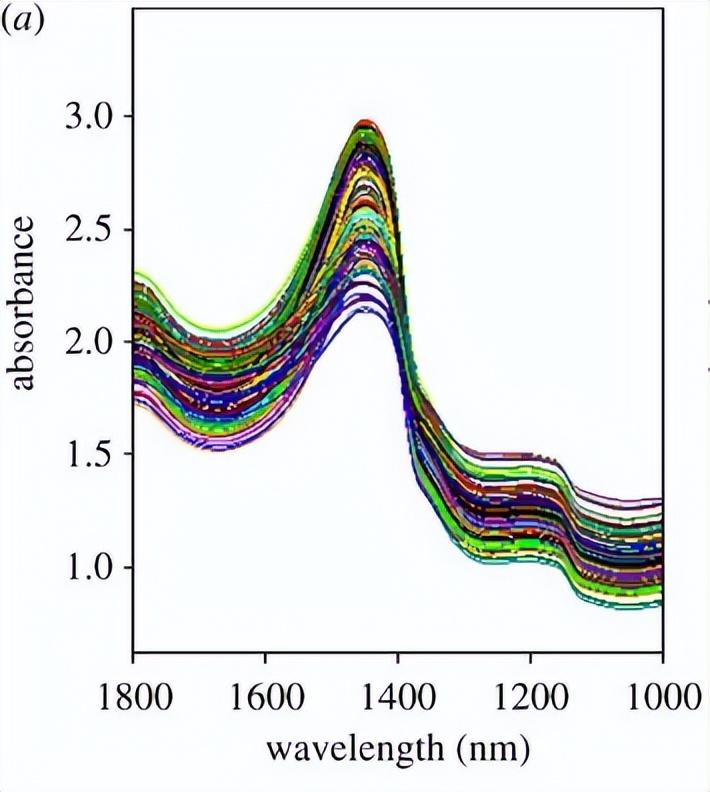
每个样本的光谱在800−2500 nm范围内以漫反射模式进行测量,分辨率为2 nm,平均扫描64次。在分析每个样品之前,记录了背景光谱。实验条件保持在恒定的温度和湿度。
在定量分析方面,使用Folch脂质提取法对刺参样品进行总脂质的提取。将样品进行甲基化处理后,进行气相色谱质谱联用测定。通过分析得到的数据,确定刺参样品的总脂肪含量,并进行统计分析以确认结果的显著性。
这些旨在开发一种有效且准确的方法,用于鉴定新鲜刺参的来源并测量其总脂肪含量,以帮助制定合理的质量标准和提高刺参质量控制的水平。

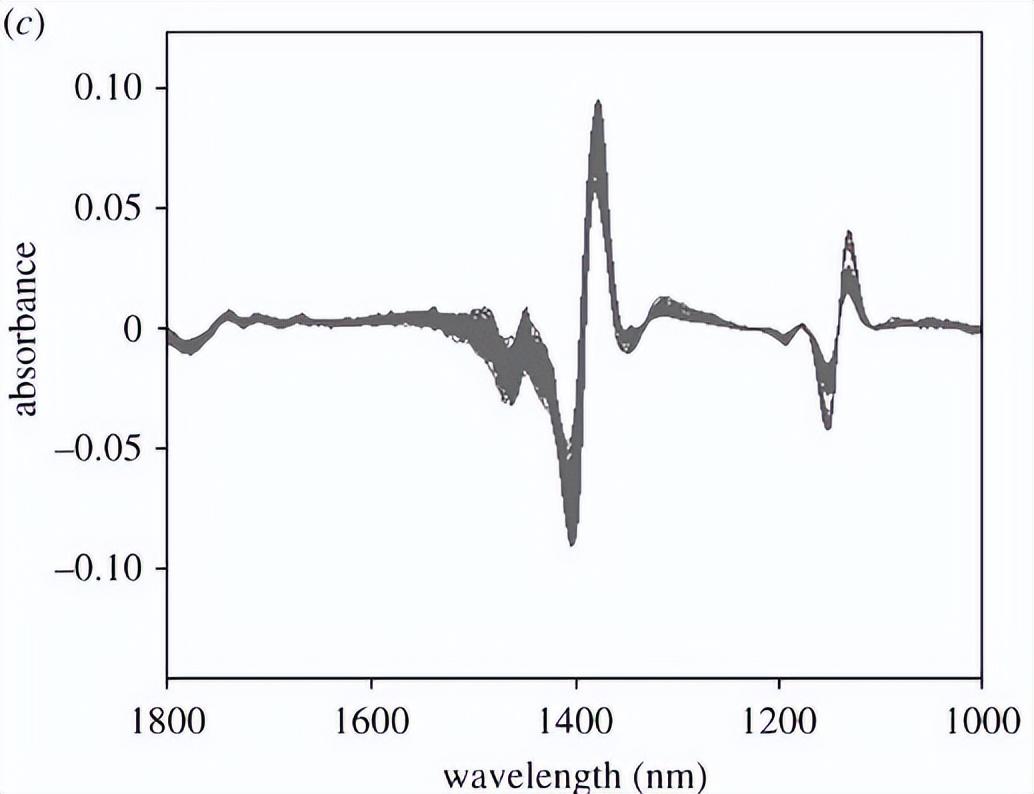
为了建立可行的NIRS识别模型和PLS模型,采用了预处理方法来消除不必要的物理信息,并放大原始光谱中的相关变化。
比较了不同的预处理方法,包括一阶导数、二阶导数、标准正态变量、乘性散点校正、向量归一化和SD-VN。为了减少SD增强噪声的影响,还使用了Savizky-Golay平滑算法对光谱进行了平滑处理。
由于仪器引起的高噪音,可见光和短波长区域被排除在外。1800-2500 nm区域也不适用,因为吸收光谱被截断为少量低能光,无法穿透样品,导致1850 nm以上的吸收光谱显示杂散光。
使用OPS算法选择合适的波长区域进行总FA含量的PLS回归,使用选定的波长区域建立识别模型,将NIR光谱数据组织成矩阵格式X ( m × n ),并对其进行预处理得到矩阵Xp。
在建立PLS模型时,以总FA含量值作为因变量 ( y ),并使用预处理的刺参样品光谱矩阵Xp进行留一法交叉验证,将数据集分为校准集和测试集。校准集用于建立模型,测试集用于验证模型的预测能力。
为了对刺参样品的来源进行分类,建立了“两步”NIRS鉴定模型。首先通过Step I模型对校准集的样品进行分类,然后将未识别的光谱输入到Step II模型进行进一步分类。选择了最佳的预处理方法、波长区域和化学计量学方法,以增强NIRS模型的预测能力。
在步骤I和步骤II模型中,分别采用了PCA-MD算法和缩放至第一范围算法作为化学计量学方法。选择性被用来评估识别模型的判别能力,它表示类别之间的分离程度。
S > 1 表示类别可以完全分离,S = 1 表示类别之间有接触,S < 1 表示类别重叠。S值越大,判别结果越好,预测模型越准确。S的计算公式如下:
S = D_D1 + D_D2
其中D表示一个类别中心到另一个类别中心的距离。计算未知谱图与校准集中平均谱图之间的距离,并通过计算每个类别的阈值来得到S值。
使用GC/MS测定了来自九个产地的刺参体壁总脂肪含量,并进行了方差分析和Tukey’s HSD事后检验。各个产地刺参总脂肪含量的标准值。
不同产地的刺参总脂肪含量之间存在显著差异。与其他来源的样品相比,莱州产地的刺参总脂肪含量在统计上更高,而霞浦产地的刺参总脂肪含量较低。
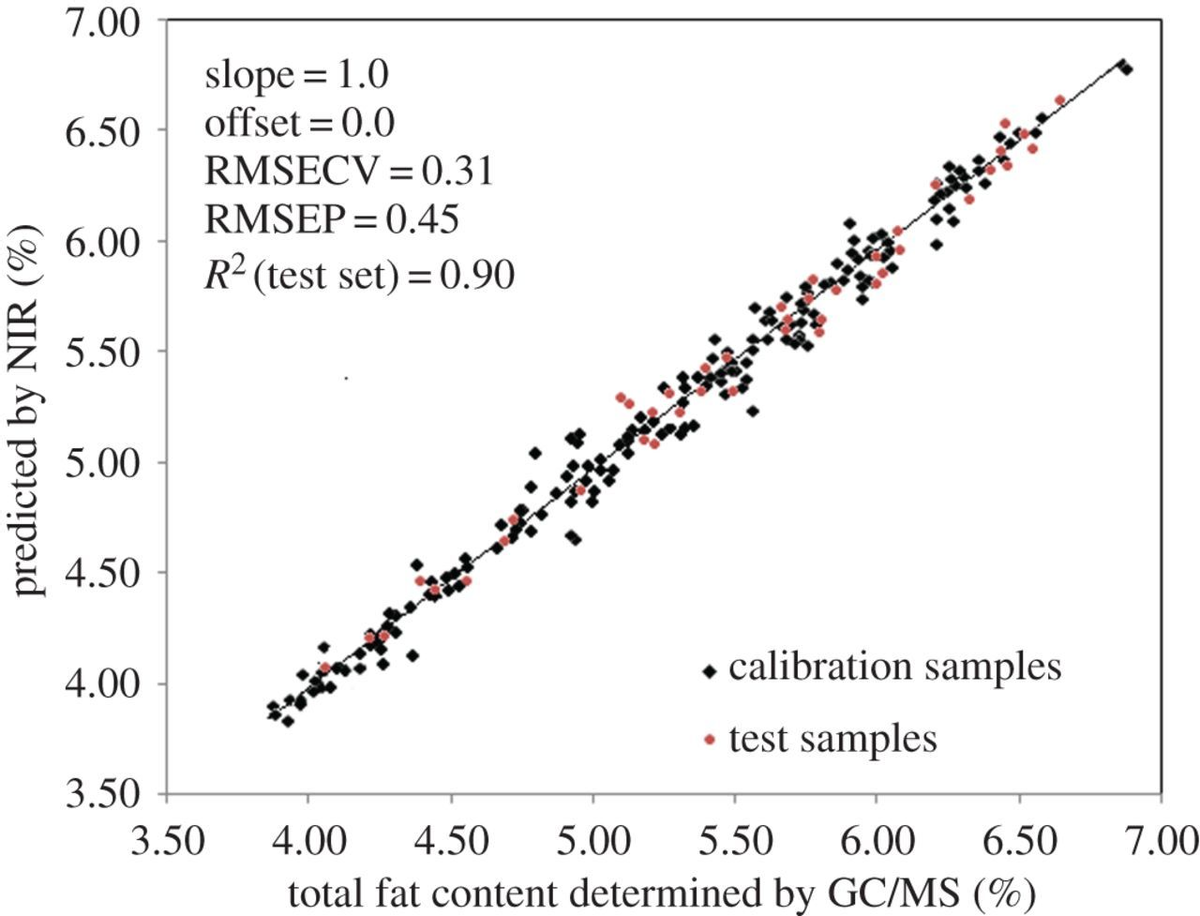
使用OPS算法来建立偏最小二乘模型,将189个刺参样品的原始光谱组织成一个矩阵格式。经过预处理研究后,选择了在交叉验证中具有最低均方根误差和最高校准交叉验证相关系数的二阶导数之前的17个谱点,并使用SG平滑处理作为定量模型。
PLS模型的潜在变量数也根据RMSECV和R2值确定。在采用17点平滑和SD预处理方法时,得到了具有8个潜在变量的PLS模型,其RMSECV为0.31,R2为0.93。
“两步式”识别模型建立流程,在在总脂肪含量PLS模型中,OPS选择了30个波长区域,这些波长区域也用于建立Step I识别模型。为了进行预处理,首先对选定的波长区域应用17点的SG平滑,然后使用PCA-MD方法。
经过Step I模型进行分类后,有49个样本由于分类不明确,因此进入串联步骤II进行进一步识别。“组步骤I或组步骤II”列中列出了与“组”列中的样品差异最小的样品,并且这些最小S值分别列在“组步骤I”或“组步骤II”列中。
以第一行的XP样本为例,经过Step I分类后,与它们差异最小的是WFD样本,Step I的S值为2.48,这表明它们可以完全分离,对于第二步分类来说不是必需的。
但对于第七行的CH样本,经过Step I分类后,与它们差异最小的是ZZ样本,其S值为0.51,这表明它们没有被分离,因此需要经过Step II分类,幸运的是Step II的S值为1.10,这表明它们已经被成功分离到正确的簇中。
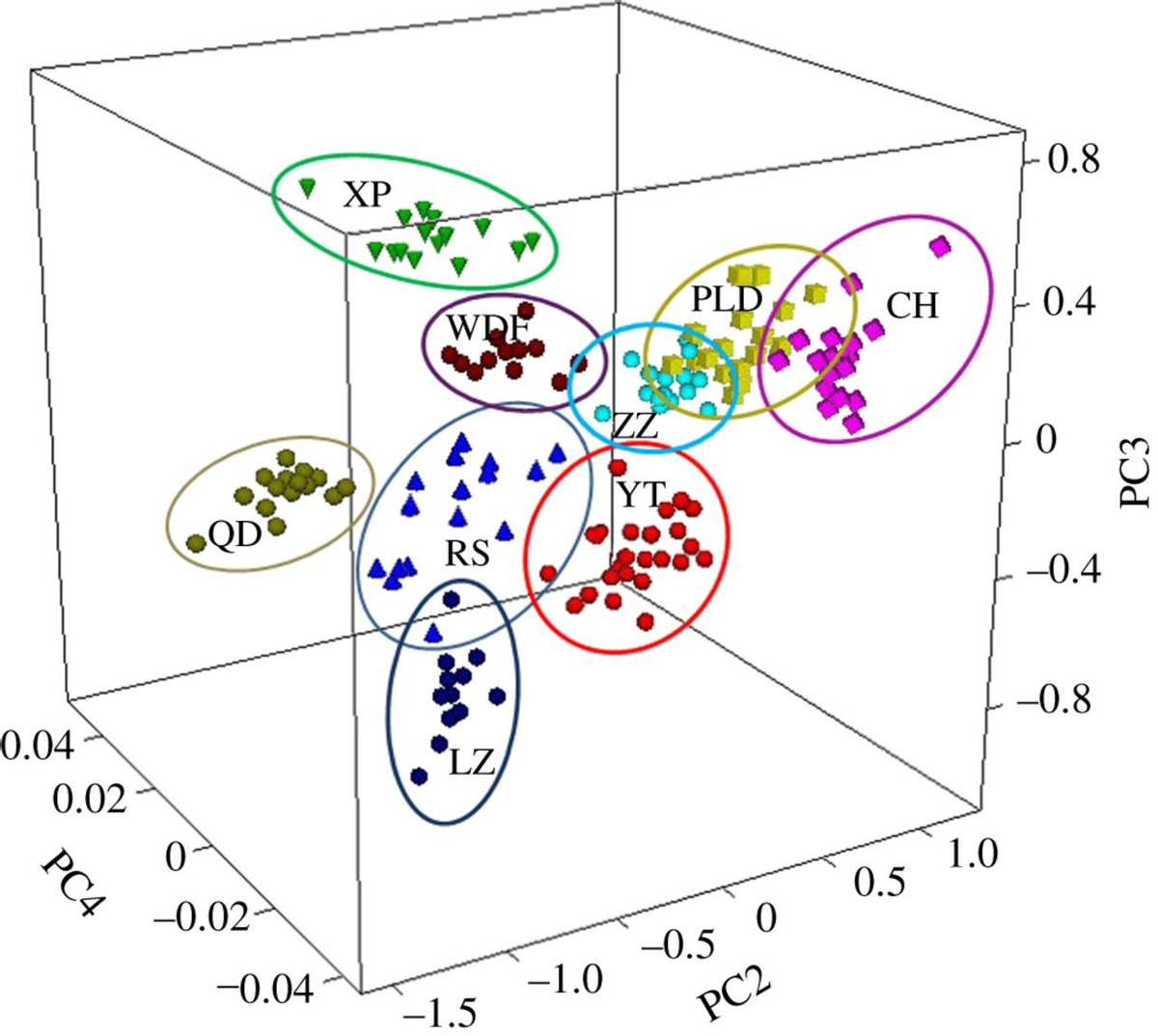
XP样本获得了最大的S I值,Step I模型中除了CH、PLD和ZZ的S I值外,其他组的S I值均大于1.06,这表明XP、WFD、QD、YT、RS和LZ产地的刺参样品之间存在显著差异。其中三维主成分空间概述了NIRS识别模型对中国海九个来源的刺参进行分类的能力。
在由PC2、PC3和PC4向量表示的三维空间中的分数图上观察到最好的辨别力。尽管PC1的方差贡献率高达83.4%,但由于PC1分类不明确,没有在模型构建中使用。据推测,PC1包含样品的主要化学信息,而不是样品之间的差异信息。
来自9个不同产地的海参样品被分为7个集中区。XP样品可以与其他来源的样品完全分离,XP样品良好的分类结果可归因于东海和北海之间显着不同的水环境和食物来源。
PLD、ZZ和CH的样品分布存在部分重叠,这与它们在黄海的邻近地理位置相吻合,导致水环境和食物来源相似。
通过步骤I模型未能成功分类的49个样本随后被串联步骤II模型分离。采用SD-VN作为预处理方法,对OPS选择的25个波长区域进行缩放至第一范围算法。CH、PLD和ZZ来源的样品的S II值均大于1.10,这表明CH、PLD和ZZ来源的刺参样品可以被正确分类。
使用建立的模型对验证集中的45个样本进行分类,没有一个样本被识别为错误的类别,海参样品虽然属于同一物种,但不同的地理区域和水环境会导致样品的光谱特征不同,从而揭示样品之间的差异。

近红外光谱技术结合化学计量学分析是一种可行的方法,能够正确分类中国海九个来源的刺参样本。
本研究开发的近红外光谱结合化学计量分析的产地溯源和鉴定方法,对中国九个产地的刺参样品展现了令人满意的预测能力,正确分类率达到了100%,所建立的PLS模型适用于海参总脂肪含量的测定。

NIRS方法不需要对样品进行任何复杂的预处理,利用反射光纤探头使得原位分析成为可能,从而实现了野生海参的在线检测,在近红外光谱方法真正应用于海参产业的产地溯源和鉴定之前,还需要更广泛的样本来提高鉴定模型的准确性和适用性




